
做一个有温度和有干货的技术分享作者 —— Qborfy
今天我们来学习 Embedding
一句话核心: Embedding = 将离散对象(文本/图像/用户行为)映射为连续向量的技术,本质是让机器通过向量空间中的相对位置理解语义关联。
通俗理解 Embedding 概念,可以理解成 每个词/图片像获得一张“智能身份证”,身份证号(向量)隐含其特征(如: 性别、 籍贯、民族等),但是在数据上展示就是一个多维向量。
然后通过“身份证号”的向量差距表示语义关联,从而实现机器理解语义。如:相似对象(如“猫”和“狗”)身份证号接近,差异大的(如“猫”和“汽车”)则相距甚远
掌握Embedding,就握住了AI理解现实世界的“语义密码本”!
是什么
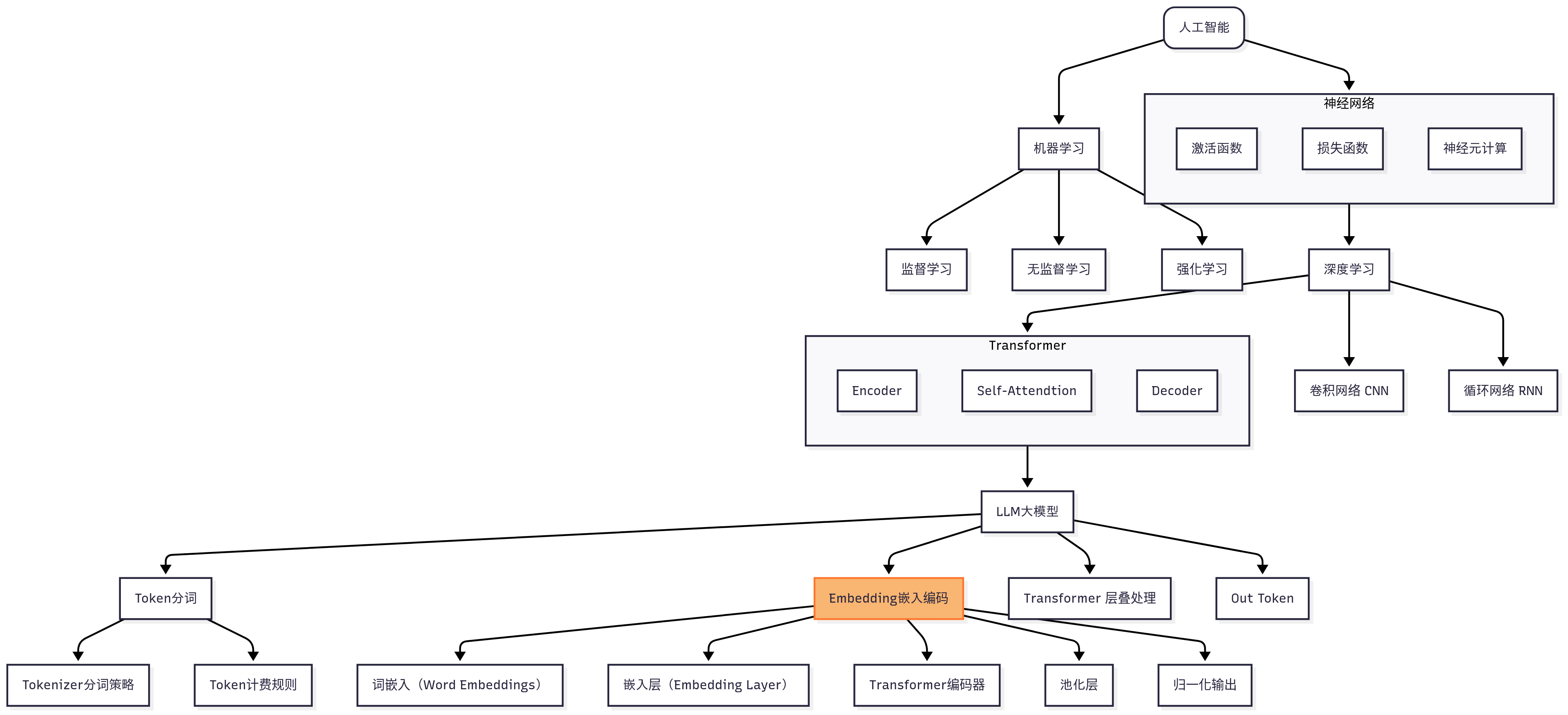
核心特性:
- 语义保留:向量距离反映内容相关性(余弦相似度>0.8→强关联)
- 可计算性:支持向量运算(如
"国王" - "男" + "女" ≈ "女王") - 降维高效:将GB级文本压缩为KB级向量
怎么做
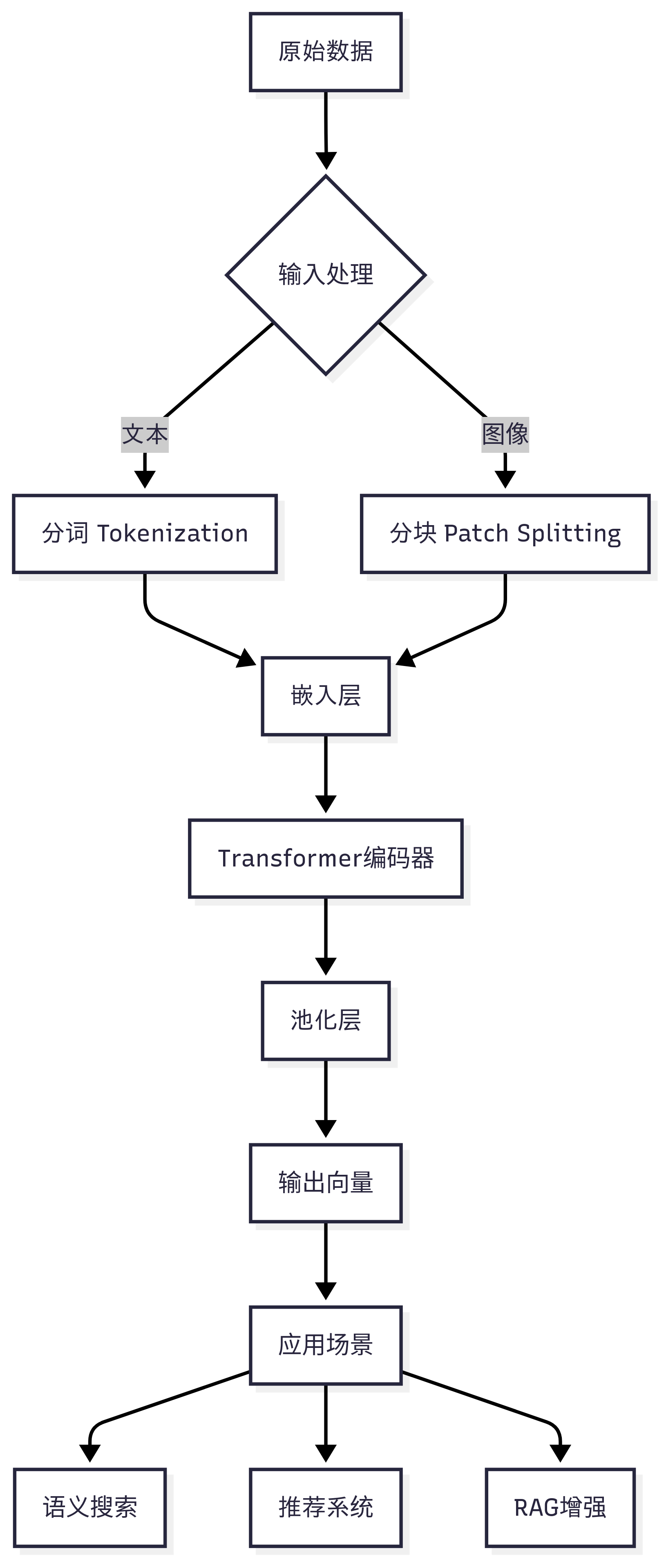
关键步骤解析:
- 输入处理:
- 文本:拆分为词/子词(如“深度学习”→
["深","度","学","习"]) - 图像:分割为16x16像素块(ViT模型)
- 文本:拆分为词/子词(如“深度学习”→
- 语义编码:
- 通过自注意力机制计算上下文关联(如“苹果”在水果/公司场景向量不同)
- 池化压缩:
- 平均池化:所有Token向量取平均
- [CLS]向量:BERT提取句子整体表征
- 归一化输出:L2归一化使向量模长为1,简化相似度计算
PS: Embedding 本质是 向量空间, 其最大的作用是计算语义关联。
池化压缩就是把多维向量压缩为1维,从而方便计算,常用压缩算法有:平均池化、[CLS]向量等。
归一化输出就是将很长的向量模长归一化,最终只输出成长度=1的向量,方便更多计算,如:使用点积可以稍微更快地计算余弦相似度。
Embedding生态
为了更好理解Embedding,还可以了解下Embedding能做什么以及周边生态。
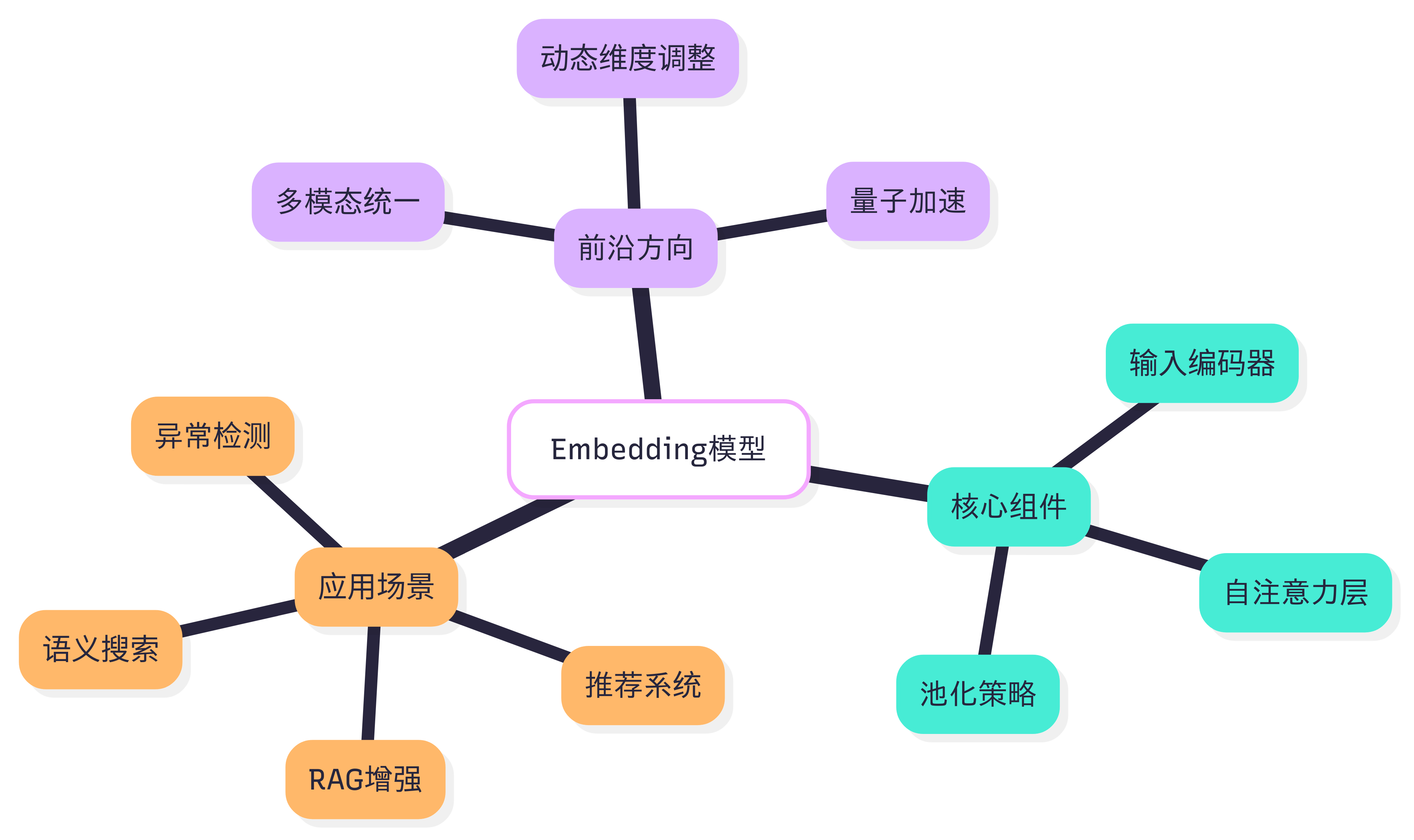
实战应用案例
理解完 Embedding概念,能让我们实际应用开发更有多选择和降低成本。
1. 电商客服意图过滤(成本降低40%)
问题:70%用户提问与业务无关(如:“今天天气?”)
解决方案
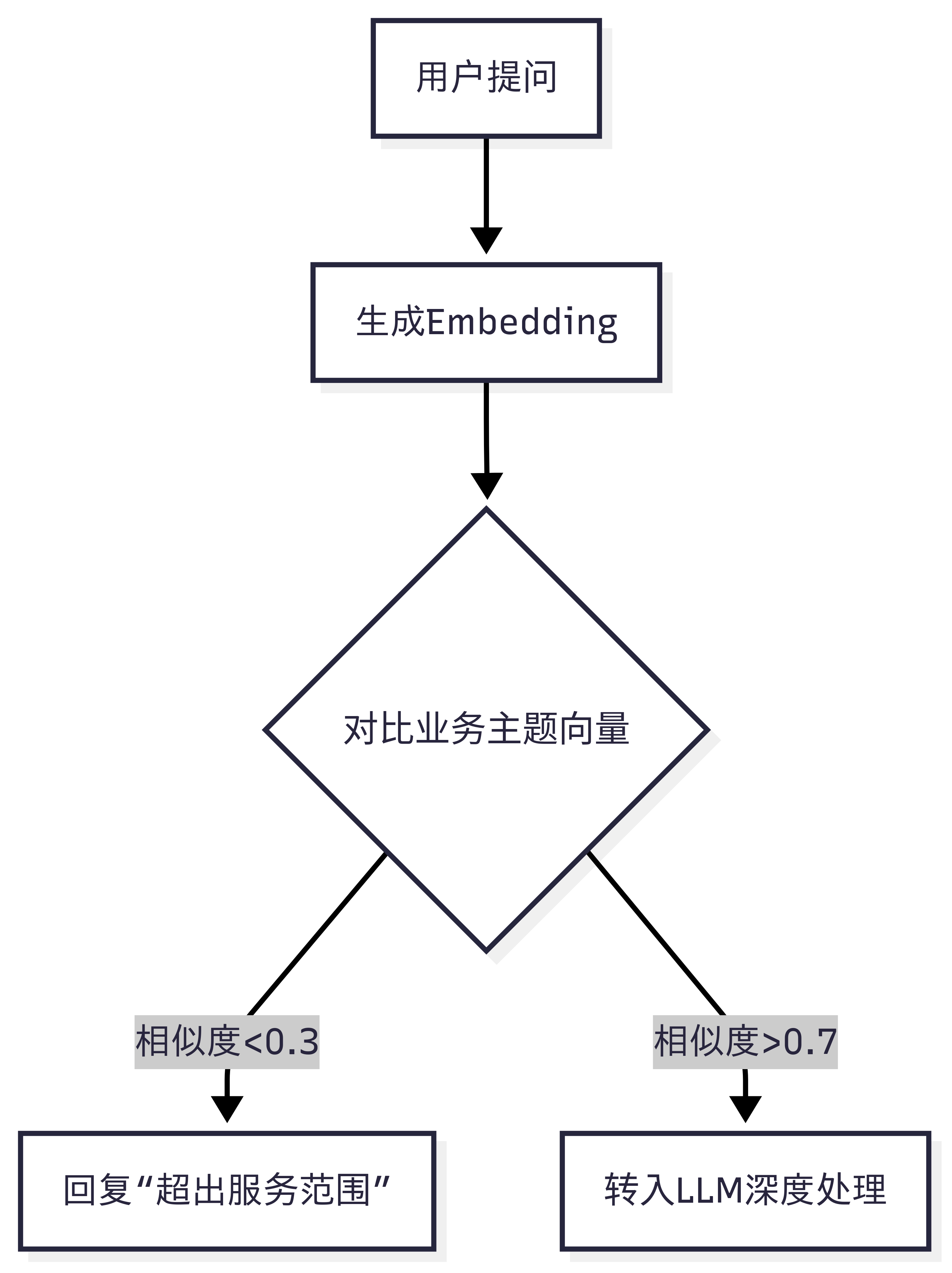
效果:减少无效LLM调用,响应速度提升3倍
2. 医疗影像语义检索
输入:病理报告文本 + CT影像切片
技术方案:
- 文本:BioBERT生成报告向量(理解“毛玻璃结节”)
- 图像:CLIP模型提取视觉特征
- 跨模态融合:共享向量空间检索相似病例
结果:诊断准确率提升35%,误诊率↓18%
常用 Embedding模型(2025最新)
| 模型 | 核心优势 | 适用场景 | 中文支持 |
|---|---|---|---|
| Qwen3-Embedding | MTEB多语言榜第1(70.58分) | 多语言检索/代码理解 | ✅ 优化 |
| BGE-M3 | 混合检索(稠密+稀疏向量) | 法律/金融精准匹配 | ✅ 强 |
| text-embedding-3 | 与OpenAI生态无缝集成 | 国际通用场景 | ❌ 一般 |
| NV-Embed | 长文本处理(32K Token) | 论文/合同分析 | ✅ 中等 |
我们通过代码实战一下,如何用 FlagEmbedding 模型计算不同文本的相似度。
1 | from FlagEmbedding import FlagModel |
冷知识
中文的“Token税”:
- 相同信息中文需比英文多消耗 40% Token(因分词更细)
- 例:“人工智能” → 英文“AI”(1 Token) vs 中文(2-4 Token)
医疗Embedding的生死权重:
- “心肌梗死”向量与“胸痛”相似度达0.93,而与“胃炎”仅0.12
- 医生借该特性快速定位疑似误诊病例
多模态幻象:
CLIP模型把“熊猫吃竹子”图片与文本向量对齐,跨模态相似度超0.9,却把“竹子手机支架”误判为关联对象
参考资料


- 本文作者: Qborfy
- 本文链接: https://www.qborfy.com/ailearn/daily/13.html
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!
