
做一个有温度和有干货的技术分享作者 —— Qborfy
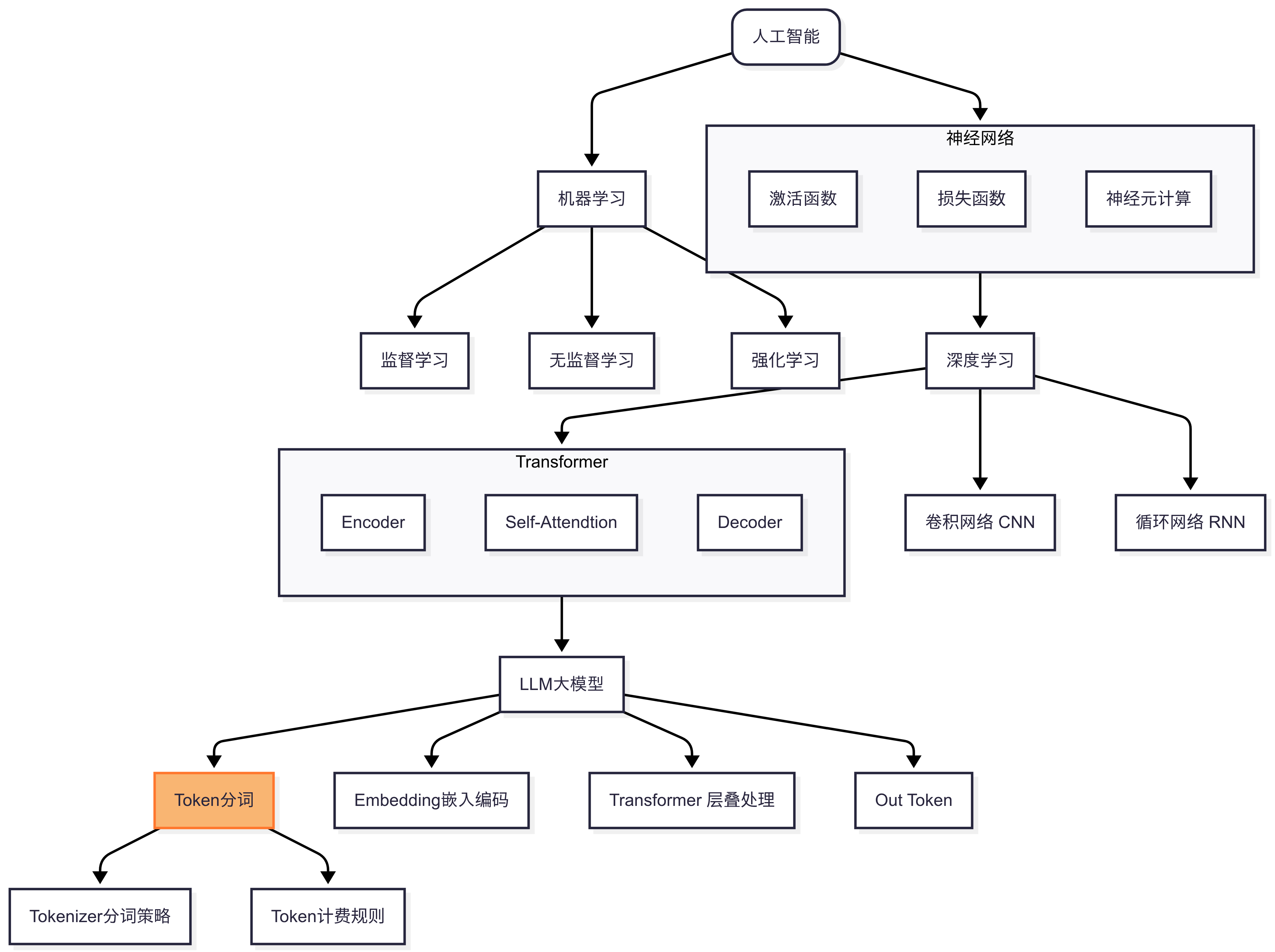
今天我们来学习 大模型Token
一句话核心: Token = 大模型处理文本的最小单元,如同原子构成物质,Token构成语言模型理解的文本世界。它可以是单词、子词、汉字或标点。
掌握Token,就握住了LLM的“算力方向盘”—— 精准控制输入、预测成本、优化生成效果。
是什么
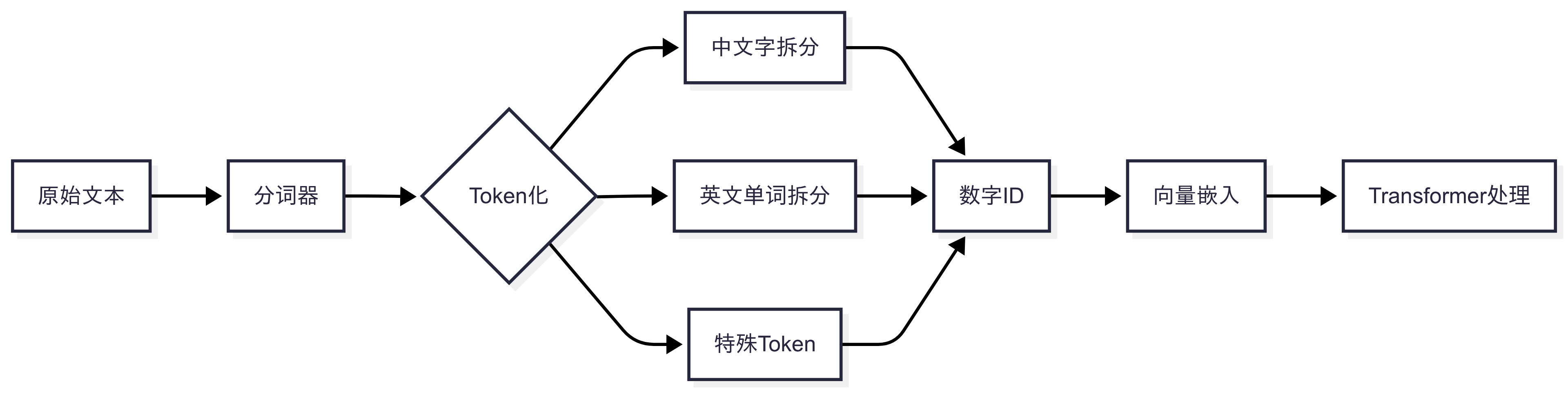
核心特性:
- 非固定长度:1个Token ≠ 1个字(例:中文“人工智能”可能拆为2个Token[“人工”,”智能”]或4个Token[“人”,”工”,”智”,”能”])。
- 数值化表示:每个Token映射唯一ID(如“AI”→[31924]),再转为向量输入神经网络。
- 计费基准:API调用按输入/输出Token量收费(如¥1/百万Token)。
此外我们还需要知道:Token计算=提问给大模型的输入+大模型的输出
怎么做
关键机制
- 中英文差异:1 个中文字符 ≈ 0.6 个 token,1 个英文字符 ≈ 0.3 个 token(因高频词合并)。
- 上下文窗口:模型单次处理Token上限(如GPT-4 Turbo:128K Token≈6.5万汉字)。
为什么要学会Token知识点呢?
- 第一,Token≈Money,目前调用所有付费大模型API,都是基于Token数计费模式
- 第二,不同大模型对于一次请求Token数是有上限的,如:GPT-4 Turbo 单次Token限制为128K
- 第三,不同大模型对于文本 Tokenizer拆分计算规则是不同的,不同模型都提供API去计算Token数
Token成本计算
场景:用户提问 “订单号DD20240815何时发货?”
- Token拆分(使用DeepSeek分词器):
1
["订单号", "DD", "2024", "08", "15", "何时", "发货"] → 7个Token
- 模型回复:
“订单已发货,物流单号SF123456” → 拆分6个Token。 - 成本计算:
- 输入7 Token + 输出6 Token = 总13 Token
- 按DeepSeek-V3定价(输入¥0.1/百万Token):
成本 = 13 × 0.0000001 = ¥0.0000013。
不同模型的分词策略
| 模型 | 分词算法 | 中文处理效果 |
|---|---|---|
| ChatGPT | BPE | 长词拆分准(“人工智能”→2 Token) |
| DeepSeek | WordPiece | 词缀捕捉强(“学习能力”→”学习“+”能力“) |
| 阿里QWen | SentencePiece | 生僻词支持优(“氪金”→保留为1 Token) |
行业真相:客服系统月耗千万Token,优化分词规则可降本20%。
动手实验
1.Tokenizer拆分在线计算
访问网站: 🔗https://platform.openai.com/tokenizer
- 输入句子实时查看Token拆分(例:“区块链”→[24775, 28638, 245, 64414])。
2.代码示例
1 | from transformers import AutoTokenizer |
3.基于Token数选择模型策略
- 64K:选Qwen2-7B(开源免费)或GPT-4 Turbo(多模态)
- 64K~200K:用Claude 3.7(长文本理解强)
- ≥200K:Gemini 1.5 Pro(需高预算)
冷知识
- 训练数据规模:GPT-3吃下3000亿Token ≈ 人类300万年阅读量。
- 128K上下文威力:可一次性处理整本《三体》(约6.5万汉字)。
- 中文的“Token 税”:同一段信息,中文消耗 Token 数比英文多 40%~100%
- Emoji 的“拆解诅咒”:❤️ 被拆为 ♥ + ️(2 Token),若用于情感分析可能被误判为“心脏符号 + 修饰符”
附:主流API的Token收费对比表
| 服务商 | 输入单价(¥/百万Token) | 输出单价(¥/百万Token) | 性价比场景 |
|---|---|---|---|
| 字节豆包(128k) | 0.8 | 0.8 | 超长文本处理 |
| DeepSeek-V3(64k) | 1~4(区分是否命中缓存,00:30-08:30打5折) | 1~4(区分是否命中缓存,00:30-08:30打5折) | 中文高精度任务 |
| 通义千问(128k) | 2.4 | 6 | 日常问答/翻译 |
| GPT-4(128k) | 70~210(10–30美金) | 210~420(30-60美金) | 英文创作/代码生成 |
| 混元(128k) | 1 | 4 | 首年免费100万token |
PS: 百万Token ≈ 60万个中文字,普通智能客服一次智能对话问答大约花费 100~500 token左右


- 本文作者: Qborfy
- 本文链接: https://www.qborfy.com/ailearn/daily/12.html
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!
