
做一个有温度和有干货的技术分享作者 —— Qborfy
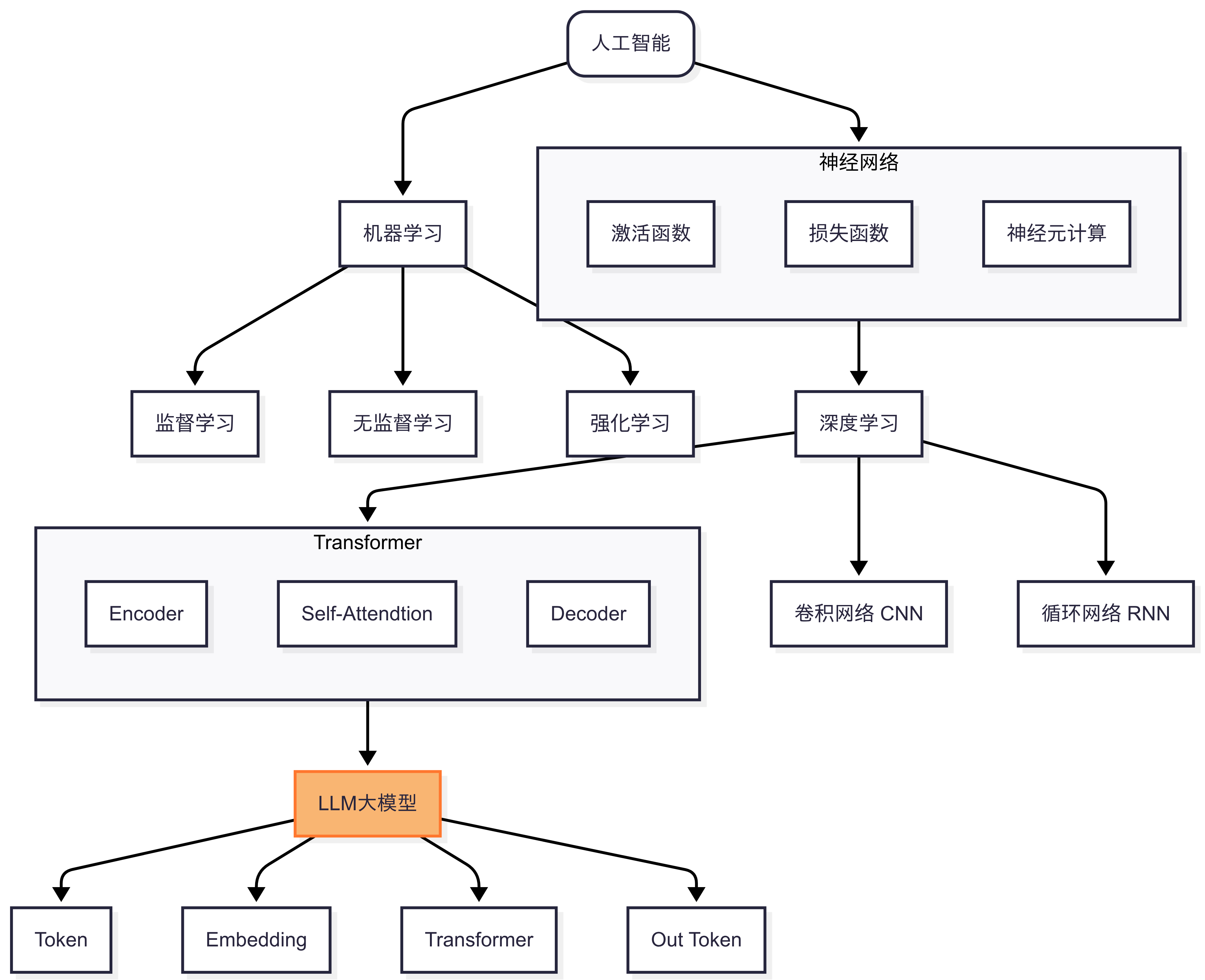
今天我们来学习 LLM大模型
一句话核心: LLM大模型(Large Language Model) = 基于Transformer架构的海量参数模型,通过万亿级文本训练,将人类语言规律压缩为数学表示,实现理解、生成、推理三位一体的通用智能。
5分钟AI知识点学到LLM大模型,其实基本上对AI知识点有大概的认知了,对于目前大多数接触AI的人第一个接触的肯定是LLM大模型,知道怎么用,但是不知道它是怎么来的。通过上面5分钟AI知识点学习,能够大概了解到一些脉络。
从我个人理解来讲,LLM大模型目前的定义来说,是AI技术发展到一定阶段的可实际应用的产品,有点类似电脑时代的 晶体管超级电脑(占地170平方米)发展到个人电脑时代,大家开始可以接触与应用到AI技术,不再局限于某个少数高端领域中。
是什么
核心突破:
- 规模效应: 百亿至万亿参数(如GPT-4:1.8万亿)突破性能瓶颈
- 零样本学习: 无需微调直接处理新任务(如翻译→摘要→代码生成)
最重要一点就是利用Transfomer架构的并行处理能力,可使用非常大规模的模型,其中通常具有数千亿个参数,甚至上万亿的参数去完成模型训练。
为什么
为什么LLM大模型能实现通用智能?
- 规模效应:量变引发质变,模型性能随参数规模(N)、数据量(D)和算力(C)呈幂律提升
- Transformer自注意力机制的革新性: 突破RNN局限理解上下文,多任务适配性实现同一个模型处理翻译、摘要、代码生成等任务
- 训练范式调整::从“死记硬背”到“举一反三”
- 预训练:通识教育阶段
- 指令微调:任务泛化能力
- 人类对齐:价值观校准
- 不可预知能力:当规模突破阈值,LLM展现“不可预测”的新能力,如:上下文学习、思维链推理、工具调用
怎么做

- 分词 Tokenization:
BPE算法拆解文本→Token序列(如“AI学习”→[“AI”,“学”,“习”]) - 嵌入表示 Embedding: 将分词Token映射为高维向量(如“猫”→[0.2, -1.3, 0.8]),捕获语义关联
- 多层Transformer堆叠:
- 自注意力机制动态计算词间权重(如“苹果”在水果/公司语境下的不同关注度)
- 前馈网络提炼特征(上下文关联)
- 概率预测 Next Token: 输出下一个Token的概率分布(如“学习”后“知识”概率=92%)
完整过程就是:数据压缩→规律学习→智能涌现
LLM三大架构对比
| 类型 | 代表模型 | 特性 | 最佳场景 |
|---|---|---|---|
| Decoder-Only | GPT/LLaMA | 自回归生成流畅 | 创作/对话(如ChatGPT) |
| Encoder-Only | BERT | 双向语义理解强 | 文本分类/情感分析 |
| Encoder-Decoder | T5 | 输入→输出转换灵活 | 翻译/摘要 |
要生成选Decoder,重理解用Encoder,复杂转换需双全
冷知识
- 能耗对比:训练GPT-3耗电≈纽约⇄旧金山航班200次,但单次推理仅需0.005度电(≈手机充电1分钟)
- 中文优势:DeepSeek模型古文生成超GPT-4,因训练数据含《四库全书》
- “幻觉”防御:金融LLM通过规则约束+概率阈值限制虚构数据,错误率<0.1%


- 本文作者: Qborfy
- 本文链接: https://www.qborfy.com/ailearn/daily/11.html
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!
