
做一个有温度和有干货的技术分享作者 —— Qborfy
今天我们来学习 Transformer算法模型
一句话核心: Transformer = 完全基于自注意力机制的序列建模引擎,通过并行计算全局依赖关系,彻底取代循环神经网络(RNN)的串行瓶颈
通俗的理解就是,原先的算法都一个接一个单词单独循环遍历相关的关联性,Transformer是把整个句子所有单词一起互相计算关联性,也可以简单理解为串行和并行区别。
是什么
“Transformer 的并行化设计,是AI从手工作坊走向工业化大生产的关键转折”—— Andrej Karpathy (特斯拉AI总监)
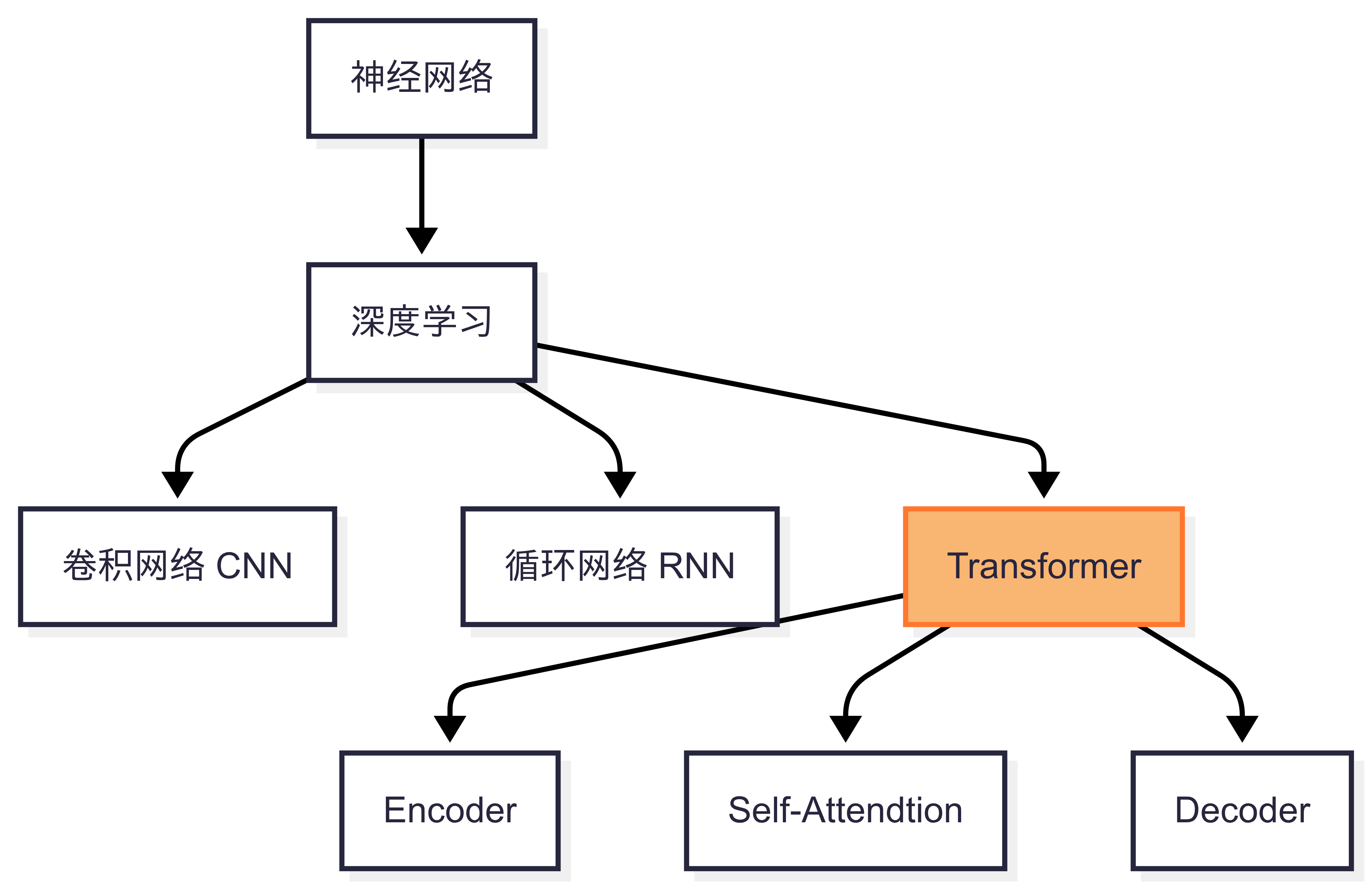
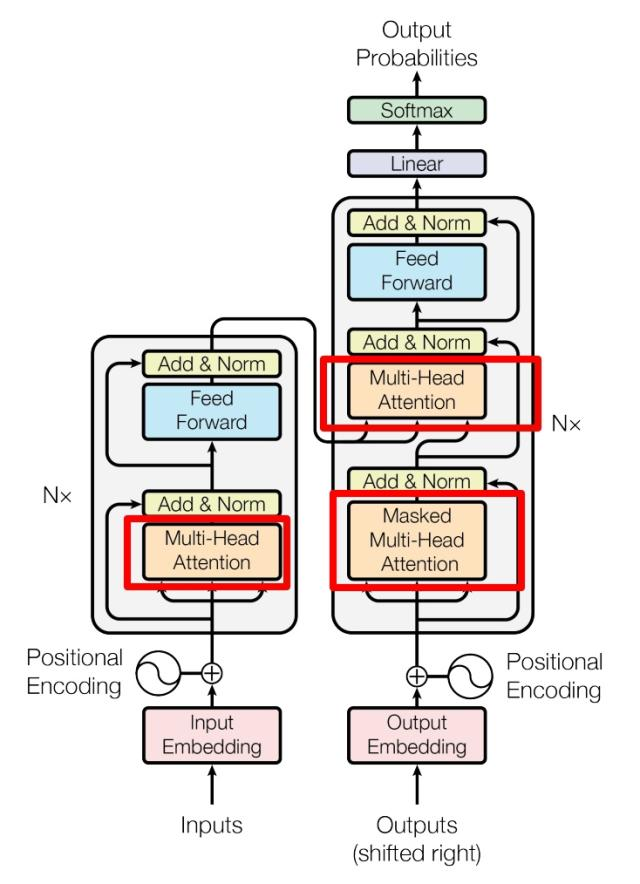
下图是对Transformer结构的简易表示
核心组成元素
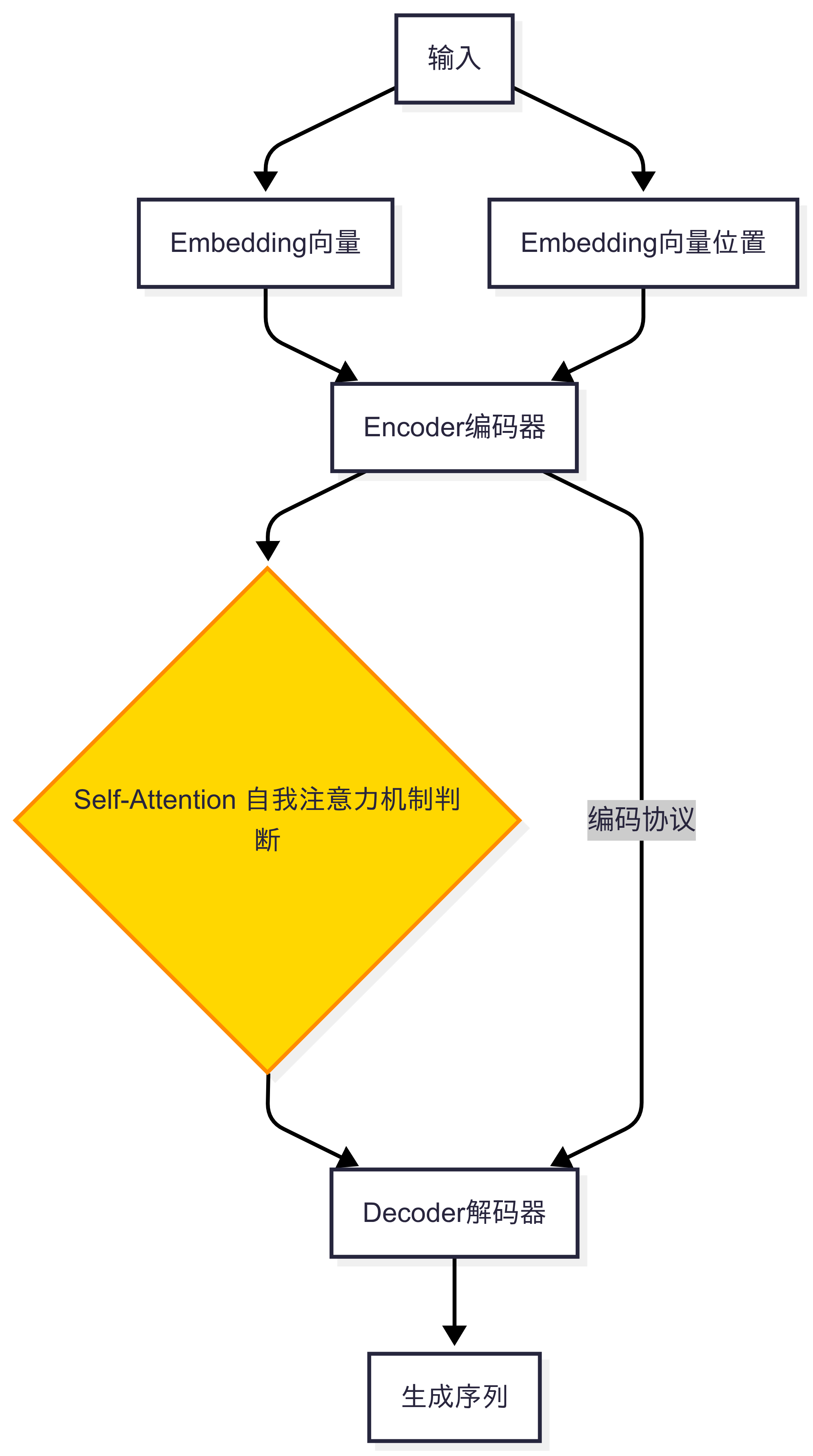
Embedding 输入: 主要包含单词向量表示和索引位置Encoder 编码器: 将输入序列(如文本、语音)转换为蕴含全局语义的高维向量表示(俗称:位置编码),捕捉序列内部的结构与依赖关系。Self-Attention 自注意力机制: 动态分配元素间关联权重, 多个Self-Attention就会组成Multi-Head AttentionDecoder 解码器: 基于编码器的语义表示,逐步生成目标序列(如翻译结果、续写文本)
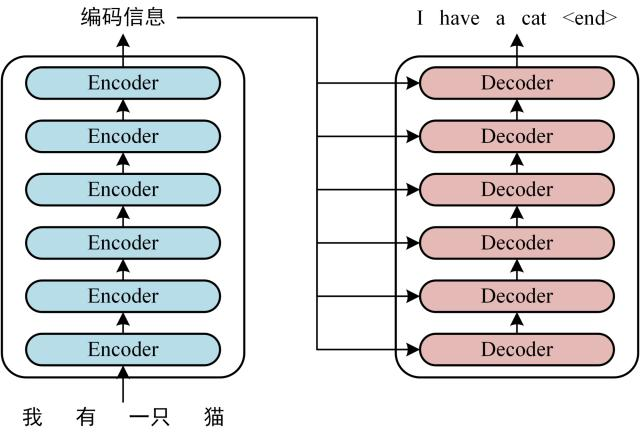
从上图,我们做一个翻译更容易理解的版本,如下图所示:
- 编码器是理解者:将杂乱输入转化为结构化知识;
- 自注意力是协商者:在知识网络中建立动态连接;
- 解码器是创造者:依据知识网络按规则生成新内容。
创建本质
- 抛弃循环结构 ,所有词同时计算关联性
- 位置编码:(正弦/余弦波)替代时间步顺序
行业应用
| 场景 | 代表模型 | Transformer 的贡献 |
|---|---|---|
| 机器翻译 | Google Translate | 长句翻译流畅度↑37% |
| 文本生成 | GPT-4 | 生成连贯性↑82% |
| 图像识别 | ViT | ImageNet 分类错误率↓15% |
| 蛋白质结构预测 | AlphaFold | 预测精度超越实验方法 |
冷知识
0.2 BLEU分的胜利:
Transformer 在机器翻译任务中仅比 LSTM 高 0.2 BLEU 分,但因 10倍训练速度 引发革命位置编码的物理隐喻:
位置编码的波长从 $2\pi$ 到 $10000\cdot2\pi$ → 相当于给模型装上 从毫米到千米的刻度尺注意力头的“专长”:
- 头1:检测主谓一致(如 “dogs” → “eat”)
- 头4:捕捉介词搭配(如 “depend on“)
- 头7:识别指代关系(如 “it” → “animal”)
能耗对比:
训练 BERT-Large 耗电 ≈ 纽约⇄旧金山航班往返40次,但推理单次仅需 0.005度电
参考资料


- 本文作者: Qborfy
- 本文链接: https://www.qborfy.com/ailearn/daily/10.html
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!
