
做一个有温度和有干货的技术分享作者 —— Qborfy
经过LangGraph+LangChain系列文章的学习后, 对LangGraph有了全面,那么接下来就应该学习通过LangGraph开发工业级RAG和部署。
工业级服务需要达到以下几个要求:
- 可靠性:强调高可用性和容错性,以确保业务的连续性
- 安全性:对安全性要求极高,需要提供强大的安全保障措施,如数据加密、访问控制、安全审计等。
- 可扩展性:需要能够根据业务发展灵活扩展,支持不断增长的用户和数据量
接下来我们一起学习如何攻克工业级RAG落地的完整方案与实现。
1. 前期准备
1.1 环境准备
1.1.1 开发环境
- conda,主要用于管理不同版本的python
- langgraph-cli,初始化项目的脚手架
- nodejs+react,开发智能客服系统前端环境
1.1.2 依赖资源环境
- 向量数据库 chroma,用于保存知识库存储
- Mysql数据库 通用知识库
- docker+docker-compose, 部署服务依赖
1.2 模型选择
RAG运行过程为: 知识库生成 -> 检索 -> 响应
- 知识库:私有的数据,主要依赖于
embedding模型生成存储到向量数据库中 - 检索:根据用户问题检索知识库,根据检索算法(如:Query、ReRanker、Rewrite等)得到问题答案
- LLM模型:根据用户问题+检索知识库返回结果形成上下文,分析得到最佳答案返回给用户
1.2.1 embedding嵌入模型
embedding模型主要作用是把知识库文档转换为向量,存储到向量数据库中, 目前主流embedding模型包含如下:
| 需求场景 | 推荐模型 | 关键优势 |
|---|---|---|
| 纯中文任务 | text2vec-large-chinese |
中文语义理解最优 |
| 中英混合检索 | bge-m3 |
多语言支持 + 长上下文 |
| 移动端/低资源部署 | bge-small-zh |
轻量高速,内存占用低 |
| 长文档处理 | nomic-embed-text |
支持 8192 tokens |
| 快速验证/API 集成 | text-embedding-3-small |
免部署,降维灵活 |
| 企业私有化 | m3e-large + 本地向量库 |
数据安全 + 定制优化 |
这里我们采用 bge-m3模型作为RAG的embedding模型,私有化部署可以参考我之前的文章02篇 AI从零开始 - 部署本地大模型 DeepSeek-R1。
1.2.2 检索过程相关
query查询:在向量数据库中查询与用户提问最相关的数据,通常使用向量数据库提供的向量检索功能,返回与用户提问最相关的文档。Reranker重排序:用于优化初步检索结果的排序,确保最相关的文档优先传递给大语言模型(LLM),从而提升生成答案的准确性和效率,常用的算法有:BM25、DPR、BERTRank等。Rewrite重写:主要是针对用户提问进行重写,以提升检索结果的准确性和相关性,常用的算法有:BERT、T5、GPT-3等。
通过这三个步骤可以在知识库检索的召回率和回答用户问题的精确率之间保持一个平衡,从而提升知识库返回的检索结果与用户问题回答的相关性。
召回率: 俗称查全率或找回率,定义为实际为正的样本中被预测为正样本的概率。
举个例子理解,就是有用户提问在知识库检索返回的结果数量为M,如果正确相关为N,那么召回率=N/M。
召回率越高说明算法模型对检索相似性要求越严格。
本次实战采用bge-m3模型作为RAG的query查询模型,DPR作为Reranker重排序模型,BERT作为Rewrite重写模型。
1.2.3 response响应模型
响应模型:根据用户问题+检索知识库返回结果形成上下文,分析得到最佳答案返回给用户,其中需要注意一下几点:
- 上下文融合(Context Fusion):不仅仅要融合用户问题,还要融合检索结果,这样才能保证生成的答案更加符合用户需求。
- 幻觉抑制(Hallucination Suppression):通过提示词指令限制模型仅基于上下文生成答案,避免生成不相关的答案。
- 逻辑连贯性(Logical Coherence):多文档推理和因果链构建,强制生成分步骤推理框架
response响应模型采用目前主流大模型就好,如:LLaMA、GPT-3、DeepSeek、Qwen3等。
我们在国内,所以采用DeepSeek作为RAG的response响应模型最佳。
2. 项目初始化
整体项目结构如下:
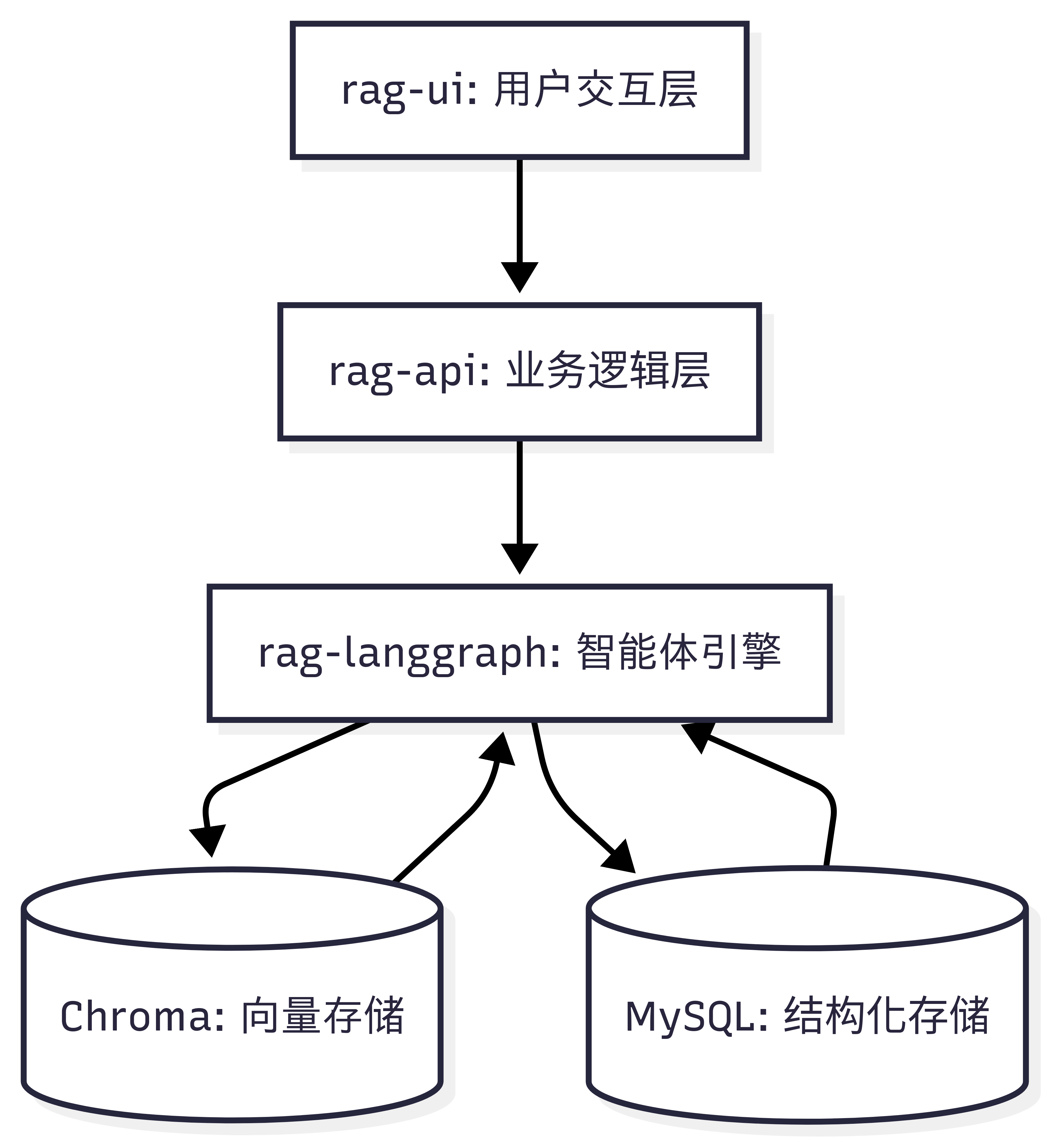
2.1 初始化LangGraph项目
1 | 安装langgraph-cli |
运行项目后可以打开http://127.0.0.1:2024查看效果。
2.2 初始化web项目
web项目界面我们采用CopilotKit作为RAG的UI界面,具体搭建步骤如下:
1 | mkdir rag-web && cd rag-web |
项目初始化已完成,以下是生成的文件和目录结构:
- package.json :配置了 Monorepo 的工作区 ( workspaces ) 和基本脚本。
- pnpm-workspace.yaml :定义了工作区范围,指向 packages/* 。
2.2.1 rag-api
api依赖nestjs,初始化命令如下:
1 | cd rag-web && mkdir -p packages/rag-api && cd packages/rag-api && pnpm dlx @nestjs/cli new . --package-manager pnpm |
调用 Langgraph
新建copilotkit.controller.ts和copilotkit.module.ts文件,内容如下:
1 | // copilotkit.module.ts |
1 | // copilotkit.controller.ts |
2.2 rag-web
1 | cd rag-web && mkdir -p packages/rag-ui && cd packages/rag-ui && pnpm create vite@latest . --template react-ts |
在src/App.tsx中引入copilotkit,内容如下:
1 | import { useState } from 'react' |
运行 pnpm dev,打开http://127.0.0.1:3000查看效果。
2.3 搭建Chroma向量数据库
通过docker-compose启动Chroma数据库,文件在docker-compose.yml,内容如下:
1 | version: '3.8' # Specifies the Docker Compose file format version |
只是先搭建好,后续会将知识库数据导入到Chroma中。
3. 项目部署
3.1 LangGraph部署
LangGraph-Cli初始化项目后会自动生成 Dockerfile,内容如下:
1 | FROM langchain/langgraph-api:3.11-wolfi |
后续部署只需要将项目打包成镜像,然后通过 docker-compose 运行即可。
3.2 Web项目部署
web项目包含两个项目,rag-api和rag-ui,可以通过pnpm build+ dockerfile打包成镜像,然后通过 docker-compose 运行即可。Dockerfile目录如下:
1 | 编译 Monorepo项目 |
rag-api dockerfile
1 | # rag-api dockerfile |
rag-ui dockerfile
前端项目利用nginx作为静态资源服务器,所以需要将前端项目打包成静态资源,然后通过nginx作为静态资源服务器。
1 | # rag-ui dockerfile |
docker-compose.yaml运行
通过docker-compose运行项目,内容如下:
1 | version: '3.8' # Specifies the Docker Compose file format version |
其中rag-api和rag-ui的端口映射,可以根据实际情况修改,在 rag-ui项目中 修改 nginx 配置文件,将 4123 端口服务映射到对应 location /api中,具体如下:
1 | server { |
总结
经过本文学习,主要目标是搭建可以正式使用的 RAG 项目服务,本问主要介绍了:
- 如何使用LangGraph-Cli搭建LangGraph
- 如何使用CopilotKit搭建智能问答助手前端
- 如何将项目打包成镜像,然后通过 docker-compose 运行项目
- 如何通过 nginx 配置文件,将 rag-api 服务映射到 rag-ui 项目中
下一章我们讲学习如何开发 Langgraph加载各类知识库,以及如何将知识库数据导入到Chroma中。
参考资料


- 本文作者: Qborfy
- 本文链接: https://www.qborfy.com/ailearn/ai-learn12.html
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!
